Instance crashed with ORA-600[15709] in 11.2.0.3
Recently instance was crashed several times with Internal errors(ORA-00600). This below practice is based on “11.2.0.3”, Below work around provided after working with Oracle Support.
Tue Feb 19 17:40:14 2013 System State dumped to trace file /u00/app/oracle/diag/rdbms/ckpt/ckpt/trace/ckpt_smon_4850.trc Errors in file /u00/app/oracle/diag/rdbms/ckpt/ckpt/trace/ckpt_smon_4850.trc: ORA-30319: Message 30319 not found; product=RDBMS; facility=ORA Errors in file /u00/app/oracle/diag/rdbms/ckpt/ckpt/trace/ckpt_smon_4850.trc (incident=48515): ORA-00600: internal error code, arguments: [15709], [29], [1], [], [], [], [], [], [], [], [], [] ORA-30319: Message 30319 not found; product=RDBMS; facility=ORA
Some more detailed information from the DIAG trace file
SO: 0x1367b2528, type: 4, owner: 0x135587f90, flag: INIT/-/-/0x00 if: 0x3 c: 0x3 proc=0x135587f90, name=session, file=ksu.h LINE:12624, pg=0 (session) sid: 181 ser: 1 trans: (nil), creator: 0x135587f90 flags: (0x51) USR/- flags_idl: (0x1) BSY/-/-/-/-/- flags2: (0x409) -/-/INC DID: 0002-, short-term DID: txn branch: (nil) oct: 0, prv: 0, sql: (nil), psql: (nil), user: 0/SYS ksuxds FALSE at location: 0 service name: SYS$BACKGROUND Current Wait Stack: 0: waiting for 'pmon timer' duration=0x12c, =0x0, =0x0 ..................................................................................................... Trace Bucket Dump End: default bucket for process 14 (osid: 4850, SMON) [ktpr_cleanup_check] -- END Fatal internal error happened while SMON was doing active transaction recovery. error 474 detected in background process ORA-00600: internal error code, arguments: [15709], [29], [1], [], [], [], [], [], [], [], [], [] ORA-30319: Message 30319 not found; product=RDBMS; facility=ORA kjzduptcctx: Notifying DIAG for crash event ----- Abridged Call Stack Trace ----- ksedsts()+461<-kjzdssdmp()+267<-kjzduptcctx()+232<-kjzdicrshnfy()+53<-ksuitm()+1332<-ksbrdp()+3344<-opirip()+623<-opidrv()+603<-sou2o()+103<-opimai_real()+266<-ssthrdmain()+252<-main()+201<-__libc_start_main()+244<-_start()+36 ----- End of Abridged Call Stack Trace -----
From above trace shows, Instance was crashed while SMON performing active transaction recovery. After killing a large running transaction then database seems to hang, or smon and parallel query servers taking all the available cpu.In fast-start parallel rollback, the background process Smon acts as a coordinator and rolls back a set of transactions in parallel using multiple server processes. Fast start parallel rollback is mainly useful when a system has transactions that run a long time before comitting, especially parallel Inserts, Updates, Deletes operations. When Smon discovers that the amount of recovery work is above a certain threshold, it automatically begins parallel rollback by dispersing the work among several parallel processes. There are cases where parallel transaction recovery is not as fast as serial transaction recovery, because the pq slaves are interfering with each other. It looks like the changes made by this transaction cannot be recovered in parallel without causing a performance problem. The parallel rollback slave processes are most likely contending for the same resource, which results in even worse rollback performance compared to a serial rollback.Our database had 50GB of undo tablespace. you can get more information from the MOS Note()
The below graph will give you more evidence from below OSWatcher Graph.
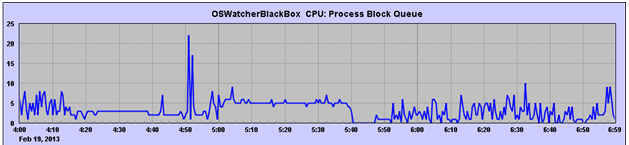
The process Block Queue was very high and eventually hung hence crashed the database. Now what’s next? As usual for any internal errors straight away revised MOS for any listed bugs, Fortunately found it as bug with MOS note (SMON may fail with ORA-00600 [15709] Errors Crashing the Instance [ID 736348.1])
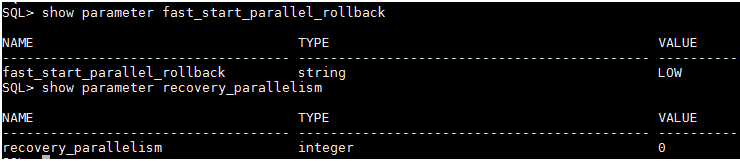
The above MOS note, refers to either apply patch and change parameters, But we are already in 11.2.0.3 and hence after working with SR, Oracle Support suggested to set “FAST_START_PARALLEL_ROLLBACK” to “FALSE“.
Conclusion:-
Oracle says even though 11.2.0.3 some of their customers have seen these error messages in alert logs and their suggestion is altering the parameter using, Alter system set fast_start_parallel_rollback=false and restarting instance might help us avoid these parallel fast start rollback issues.But the drawback to setting fast_start_parallel_rollback=LOW is Sometimes Parallel Rollback of Large Transaction may become very slow. And if we set fast_start_parallel_rollback=false from LOW based on this one time incident then some of the transactions that would be rolled back faster might slow down.
— Happy Reading —